Convergent Evolution: Snowflake and Databricks
Snowflake and Databricks emerged as two companies with differing products and business models; today they frequently butt heads due to converging platforms and overalpping company profiles

Coke vs Pepsi; Yankees vs Red Sox; Sith vs Jedi - red and blue rivalries hold the world in their hands. Snowflake vs Databricks might just determine the fate of the universe.

Snowflake and Databricks constantly compete as blue-chip offerings along the data value chain. Within a sample size of two, Databricks and Snowflake exemplify the merits and considerations between open-source and closed-source software. To better analyze these two companies and their relative business models, it’s important to understand their origins and product offerings.
In a nutshell:
Snowflake takes an “IOS” approach to software development and customer experience. Its roots are nested in structured data and have since broadened to unstructured data.
Databricks utilizes a more open-source “Android” approach to its data solutions. Originally specializing in unstructured data, the company has also expanded to offer structured data products.
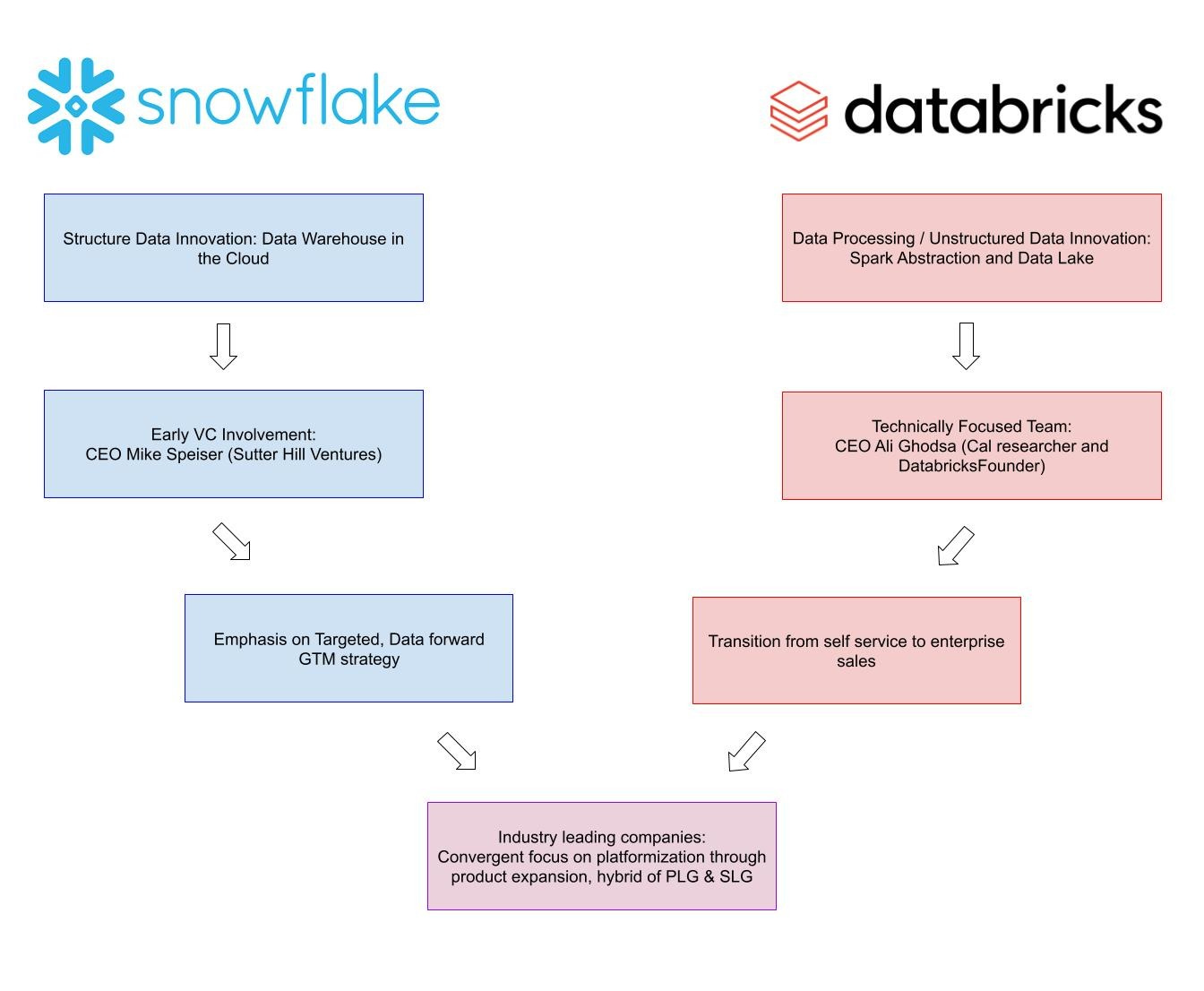
In 2012, Benoît Dageville, Thierry Cruanes, and Marcin Żukowsk noticed an opportunity to offer data warehouses in the cloud. As the name suggests, data warehouses function as a central repository for organizations to house all their structured data. Structured data is data that can be cleanly organized in a spreadsheet or document, ex: sales, inventory, customer names, and emails. While Snowflake did not invent warehouses, the team produced a key innovation - using a cloud-native approach to separate compute from storage. The team came up with the name “Snowflake” as Snowflakes are born in the cloud.

Breaking down these buzzwords, cloud-native refers to Snowflake’s computational stack. Rather than fulfilling hardware demands with servers built into a company’s physical premises, Snowflake facilitated software interactions by sending commands and requests to hardware located within a data center hosted by platforms like AWS (Amazon Web Services), Microsft Azure, Oracle, or GCP (Google Cloud Platform).
Snowflake’s value proposition for shifting software off-premise and into the cloud lies in the ability to separate computing and storage. By nature, on-premise solutions are constrained by their flexibility. It’s impossible to increase processing power and/or storage capacity without manually installing hardware—an expensive and time-consuming endeavor. On the cloud, Snowflake can easily increase a customer’s computing or storage by simply adjusting their hardware allotment within the central data center. Snowflake’s data warehouse was significantly more flexible than its competitors, thus removing bottlenecks for customers as they expanded.
Databricks, founded a year after Snowflake in 2013, rose from the academic and open-source community that created Apache Spark. UC Berkeley researchers built Spark in 2009 to increase data processing speeds for large datasets in machine learning use cases. At the time, developers and data engineers manipulated large datasets through job schedulers to split up massive tasks into bite-sized tasks. Hadoop Map Reduce, the industry standard at the time, essentially aggregated groups of slower-processing computers into a singular system. Compared to supercomputers, Hadoop processed slowly, but completed the same tasks.
Researchers built Spark as a faster alternative/extension to Hadoop. Without getting too technical, Spark improved on Hadoop by leveraging a faster infrastructure. Hadoop performs operations by splitting large tasks into smaller ones through a time-intensive file system that requires operating systems to travel between multiple levels of memory. Spark functions multitudes faster and across a larger set of use cases by leaning on RAM rather than a file system. This means that Spark does not have to navigate multiple levels of computer memory.

Spark offered a more efficient solution than Hadoop but struggled with ease of use and adoption. Spark developers recognized an opportunity to provide a more user-friendly layer of abstraction on top of Spark. Thus, Databricks was born. From inception, Databricks’ focus on enabling big data usecases in AI and ML led the platform to excel within unstructured data (pictures, video, and audio files). Databricks helped pioneer unstructured data storage and querying with their innovation in data lakes. While Snowflake developed data warehouses as a regimented and organized architecture to store structured data, Databricks built data lakes as a pool to store vast amounts of unstructured data.

Databricks and Snowflake originated from solving two disparate problems; their product lines and offerings have since converged causing the two to compete against each other. Both companies offer a data lake, warehouse, and lake house. As the name suggests, Data lakehouses combine the merits of warehouses and lakehouses to house both structured and unstructured data.
Snowflake and Databricks are interesting business models to compare and contrast. Despite their roots in parallel niches, the companies have since expanded to provide overlapping offerings. With similar products, the companies have made radically different business decisions. Snowflake trades publicly on the New York Stock Exchange where its market cap hovers between 35-40 billion dollars (Oct 2024). Databricks has yet to IPO but raised a $500M series I in 2023 at a $43 billion dollar valuation. Product-wise, Snowflake offers a more streamlined, plug-and-play platform, while Databricks remains open source and more fully customizable.
Both companies operate with similar usage-based revenue models rather than the typical per-seat revenue models of SaaS companies. At their roots, Snowflake typically targeted business buyers whereas Databricks focused on more technical buyers. Now, from a GTM strategy, the companies are more similar than different - leaning heavily on both PLG (product-led growth) and SLG (sales-led growth). Earlier in their lifecycles, however, the two companies serve as sterling examples of different growth strategies.
Throughout its growth, three CEOs have taken the helm at Snowflake. Mike Speiser steered the ship from inception to its emergence out of stealth in 2014; Bob Muglia captained the company out of stealth to an IPO in 2019. Since listing on the NYSE, Frank Slootman has driven the company forward.

In its early days, Snowflake’s sales team consisted of around 30 people, requiring a focused and strategic selling strategy. The team assigned 100 accounts to each rep. Of the 100, 90 were placed into an automated pipeline with the remaining 10 receiving custom targeted approaches. With limited resources and human capital, Snowflake prioritized accounts with a data-forward, ever-evolving approach. Snowflake leveraged a model to analyze its 50 fastest deals and 50 largest deals to identify promising accounts. After selecting a target, Snowflake leverages its ABM (account-based marketing) team to provide highly targeted content. in 2018, their process worked with the following tech stack and ABM :
Target - Utilize Everstring and Bombora to build out a pipeline to companies that share similar qualities to their best clients and demonstrate an intent to purchase.
Reach - Utilize Terminus and LinkedIn to create personalized content delivered to a prospective account. At this point, accounts may or may not even be aware of Snowflake as a solution possibility .
Engage - Utilize Uberflip to transition outreach from ABM to sales account manager. ABM teams create content but the process is now owned by sales accounts.
Measure - Utilize Engagio, Tableau, and Looker to prospect accounts, providing the necessary information needed to close a deal.
Snowflake integrated this stack and increased click-through rates by 149x on 1:1 ABM ads. Half of Snowflake’s content was consumed by targeted organizations. Meticulously finding accounts with a data-driven approach and patiently building out relationships allowed Snowflake to grow exponentially in its early years.
Databricks evolved out of the Apache Spark open-source community; their early go-to-market strategy leaned heavily on product-led growth within the open-source community. From 2009 to 2012, Ali Ghodsi pitched companies to integrate Spark into their own stack - none agreed. Even after Ben Horowitz invested $14 million at a $50 million valuation in 2013, Databricks continued to struggle with adoption and traction.
In 2014, rumors plagued Databricks' growth. Would-be early adopters were optimistic about the solution but believed that a user's memory bottlenecked Databricks’ promised use cases. They believed that even if Databricks could operate on vast quantities of data, a user’s hardware constraints would prevent them from doing so. Even though it wasn’t true, the rumor severely hindered Databricks’ growth.

Ghodsa and his team set out to eliminate this rumor. Rather than traditional marketing strategies, Databricks broke a world record by sorting 1 petabyte (1,000 terabytes) of data in just under four hours - 4x faster than the previous record. More importantly, they completed the feat using far less than 1 petabyte of memory, destroying any doubt of user memory limiting Databricks’ potential.
Databricks capitalized on their accomplishments and caught the media’s attention. Less than a year in 2015 later they topped Gartner’s hype cycle and generated a million dollars in annual revenue. In 2016, Databricks took off. Ali Ghodsa replaced Ion Stoica as CEO, and the company pivoted from a tech product to a revenue company. While Ghodsa envisioned Databricks as a bottom-up, self-service platform where users would simply swipe a credit card in return for usage credits, the company quickly realized their product, a platform for massive datasets, and their target market, large enterprises demanded a different approach. A pure bottom-up product-led growth strategy wouldn’t work for two reasons.
Large enterprises have complex buying processes: These involve procurement departments, legal teams, and budgeting procedures overseen by CFOs, making a simple self service payment strategy insufficient.
Demonstrating value for sophisticated products requires a dedicated salesforce: Improving specific metrics by a small percentage may not seem immediately compelling, but a skilled sales team can effectively communicate the long-term value and ROI to enterprise clients
Ghodsa shifted the company away from PLG and invested heavily in enterprise sales; Databricks started paying their sales team a base salary of $350,000. Furthermore, Databricks began to develop proprietary versions of their open-source software, especially targeted toward enterprise use cases. Databricks found rapid success as they shifted their GTM strategy. A year later, in 2017, the company closed its first million deal and ended the year with $40 million in recurring revenue. Revenue continued to double for the next three years.
Evolutionary convergence characterizes how discrete animal species independently evolve into similar forms. Bats and birds both evolved wings to best survive their respective ecosystems. Zooming out, in a similar manner, Snowflake and Databricks have converged into tech behemoths offering similar products with similar pricing and GTM strategies.